✖





やりたいのは 1文字だけの改行の拒否 - Hail2u のようなことの延長です。長めの見出しがブラウザによって改行されると、どうもバランスが悪くなったり可読性が微妙になることが多い。これをなんとかする。
元の高さから変わらないことというのは行数を変えないということです。これを制約にしてページ全体の高さに影響を与えないようにすることで、非同期的に行数を調整しても閲覧に支障がないようにという意図があります。
「各行のバランス」はできるだけ行ごとの幅を揃えるという意味でいっています。基本的に幅が揃うことはないので、あくまでできるだけです。また、揃わない場合には一番下の行が一番長くなるようにします。これはデザイン上、重心が下になるほうが安定して見えるからです。
また、このサイトにも適用済みです。
いわゆる形態素解析での単語単位の「わかち書き」だと分割されすぎてしまいます。基本的に文節単位で改行するのが適切ではないかと思うので、文節単位のわかち書き機みたいなのが欲しくなります。
そこで TinySegmenterMaker を使ってみました。TinySegmenter を任意の学習データから生成できる優れものです。TinySegmenter 自身は言語非依存のアルゴリズムのため、一般的な形態素解析の分割位置とは違う分割でも学習さえさせれば動いてくれそうです。
適当なコーパスを用意できなかったため、とりあえず自分で書いた日記 (これ) の過去ログを全て MeCab で解析し、副詞などを結合する処理を加えたあとにスペース区切りで出力し、TinySegmenterMaker の入力としました。学習データ的に汎用性は落ちますが、そもそも自分のサイト用なのでまぁいい気もします。
そんなに元データは多くありませんが結構時間がかかりました。
なお分割時の MeCab 辞書に mecab-ipadic-neologd も入れてます。不必要な分割が減ることを期待しています。
1行に収まっている場合は処理しません。
場合によって全く改行位置を調整できないケースも生じます。つまり各行に文字がいっぱいっぱいに詰まっている場合、調整できません。この場合も諦めてブラウザにまかせます。ただ、最後のセグメントには改行禁止ゼロスペース文字を入れることで1文字だけ残るというのは可能な限り避けます。
文字幅の計算には canvas の measureText を使っています。カーニングやリガチャなどが適切に反映されない可能性がありますが、現時点だとこれ以上良い方法がない気がします。
Webフォントを使う場合、ロードされていることを実行前に保証する必要があります。document.fonts.ready がちゃんと使えればいいんですが、Safari の挙動がおかしいので使えませんでした。
そこで以下のようにしてWebフォントのロードを判定しています。
function webfontReady (font, opts) {
if (!opts) opts = {};
return new Promise(function (resolve, reject) {
var canvas = document.createElement('canvas');
var ctx = canvas.getContext('2d');
var TEST_TEXT = "test.@01N日本語";
var TEST_SIZE = "100px";
var timeout = Date.now() + (opts.timeout || 3000);
(function me () {
ctx.font = TEST_SIZE + " '" + font + "', sans-serif";
var w1 = ctx.measureText(TEST_TEXT).width;
ctx.font = TEST_SIZE + " '" + font + "', serif";
var w2 = ctx.measureText(TEST_TEXT).width;
ctx.font = TEST_SIZE + " '" + font + "', monospace";
var w3 = ctx.measureText(TEST_TEXT).width;
console.log(w1, w2, w3);
if (w1 === w2 && w1 === w3) {
resolve();
} else {
if (Date.now() < timeout) {
setTimeout(me, 100);
} else {
reject('timeout');
}
}
})();
});
} 本当は各形態素境界ごとにスコアリングして、読みやすい順に改行を加えるみたいなことができればいいんですが、僕の技術力だとむずかしそうです。クライアント幅によるという性質上、処理はクライアントサイドでやる必要がありますが、そうすると実行ファイルサイズも問題になってきます。
そもそも学習データとして「適切な改行位置」を与えるのが難しい問題があります。Cabocha を使えばもうちょっとマシになるでしょうか?
「下のほうを長くする」という方針がいまいちだと思います。意味的に区切れるところを優先して区切るのが正しいと思われます。
なんかどうも boost_system も必要でした。以下のようにコンパイルしました。
g++ -I/usr/local/include -L/usr/local/lib -DMULTITHREAD -lboost_thread-mt -lboost_system -O3 -o train train.cpp
あと train に引数を与えないとマルチスレッドで処理されませんでした。8スレッドでやるなら -m 8 を加えます。
./extract < /tmp/corpus.txt > features.txt ./train -t 0.001 -n 10000 -m 8 features.txt model ./maker javascript < model
https://github.com/cho45/midashi-kaigyo あまり整理されてません。
ブコメ で教えてもらいましたが、Google がまさに同じことをやってました。
Google の NL APIを使っているみたいです。
文字を変形させるという発想がなかったのですが、編集系の識者のかたから長体かけつつ字送り詰めて押し込んだりします
という意見をいただきました。また、これを実現する方法として CSS transform を使えばいいのではないかという意見もいただきました。















このエントリの情報は古いです。現行 (2018年11月) のブラウザでは canvas の色の扱いが改善され、すべて sRGB で取り扱われるようになったため、以下のようなハックはできません。(できなくなったことは喜ばしいことです。)
(黒魔術) CSS の色を sRGB にあわせるには | tech - 氾濫原 というエントリを書いてから、ふと「もしかしてユーザー環境の色域 (モニタのプロファイル) を推定することができるのではないか」と思い至ったのでやってみました。
デモ: https://lowreal.net/2017/gamutdetect/
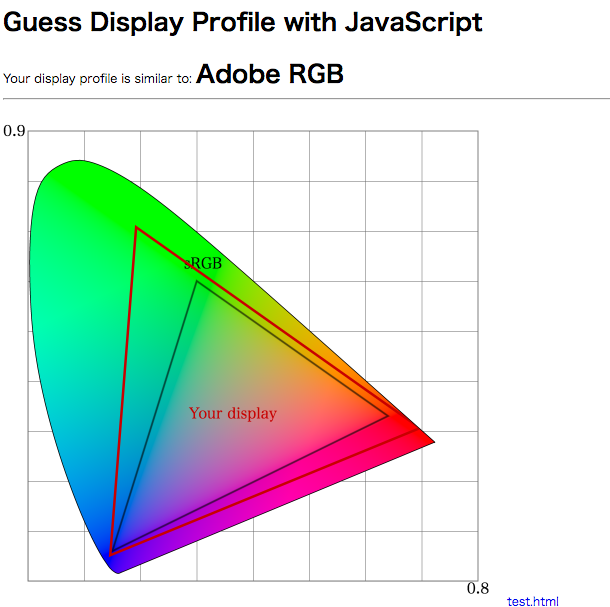
ICC Profile を埋めこんだ画像を canvas に drawImage すると、プロファイル変換されたRGB値が描かれる。getImageData 経由でピクセル値を読むことでプロファイル変換済みのRGB値が得られる。
Chrome と Firefox だけで確認しています。これらのブラウザは上記の前提があてはまるからです。基本的に不具合に近い仕様だと思うので、そのうち動かなくなりそうです。あくまでネタってことです。
Safari と IE は OS レイヤーのカラーマネジメントなのが関係しているのか、putImageData や getImageData も sRGB として扱われていそうです。
プロファイルに影響される値がとれるということは、間接的にプロファイルを推定できるはずです。具体的には sRGB プロファイルで 0,255,0 という画像データがあったとき、これは sRGB の色域で 0,255,0 という色ですが、もしモニタプロファイルが Adobe RGB など広色域であれば、取得できる値は Adobe RGB の色域のためにもっと小さい (飽和していない) 値になると予想できます。
実際にはモニタプロファイルを推定しているので「Adobe RGB の色域だ!」というのはおかしいのですが、近似として Adobe RGB / DCI P3 / sRGB の3種類の計算値の中から、近そうな色域として判定を出しています。
判定方法は sRGB で 0,255,0 (緑) の色が現在のモニタでどういう RGB 値になるかで行っています。255,0,0 (赤) と 0,0,255 (青) を判定にいれるとどうも変なので判定につかってません。もうちょっと考慮の余地がありそうです。
sRGB の 200,55,55 / 55,200,55 / 55,55,200 をレンダリングした結果を読みとり、三元一次連立方程式を3つ解いてXYZへの変換マトリクスを逆算し、あらためてRGB各頂点のXYZ値を求めるという方法でxy色図に色域をプロットするようにしてみました。中途半端な値を使っているのは飽和させないためです。
こうするとやっていることが多少わかりやすいかなという気がします。



