✖



https://chromium.googlesource.com/chromium/src.git/+/52b672b2462d6a3751a13187a1003e6fffdfbfbd
手元で確認した限りだと、バージョン 51.0.2704.63 (64-bit) で accept-encoding:gzip, deflate, sdch, br が送信されるようになっていました。
フラグとしてはバージョン49で実装されていたみたいですが、51 (2016-05-25)でようやくデフォルトでも有効になりました。リリースノートには書いてませんが、「log」をたどると上記コミットで有効になったことがわかります。
他のブラウザだと Firefox は 44 (2016-01-26)から有効になっています。
なお、Chrome でも Firefox でも brotli 対応は HTTPS 限定です。
「Chrome が新圧縮アルゴリズム対応!」みたいなニュースが流れてからだいぶ経っています。しばらくは Firefox だけ有効な状態だったので「まだかまだか」とちょくちょくチェックしていたのですが、ついにデフォルト有効になりました。これによって劇的にパフォーマンスが改善するわけではないと思いますが、accept-encoding に新しいのが加わるとわくわくします。
なおこのサイトは全体的に brotli 対応にしてあるので、開発者ツールとかで眺めてニヤニヤしています。
h2o は compress: ON にすると、レスポンスに accept-encoding に応じたオンザフライな圧縮が有効になります。ただしデフォルト状態ではcontent-type が text/ から始まる場合と +xml で終わる場合に限られているようです。
この条件に一致しない application/json などに対しても圧縮をかけたい場合、file.mime.settypes で設定すれば良いようです。すなわち
file.mime.settypes:
"application/json":
extensions: [".json"]
is_compressible: yes
priority: normal このようにすれば application/json でも自動的に圧縮してくれます。
これは file. で始まるディレクティブですが、バックエンドサーバから送るレスポンスに対しても(リバースプロキシとしても)これで圧縮がかかるようになります。


http://www.sqlite.org/withoutrowid.html WITHOUT ROWID 最適化について
SQLite は常に暗黙的な rowid カラムを持っていることになっている。これはカラムとして明示することもできるし、interger primary key として定義されたフィールドは暗黙的な rowid の代わりにすることができる。SQLite ではこの rowid が基本のプライマリキーになっている。
適当な数値をプライマリキーにしたい場合はこれで全く問題ないが、複合キーだったり文字列をプライマリキーにしたい場合、その表面上のプライマリキーとは別に rowid カラムができる。このケースでは表面上のプライマリキーを使って SELECT しようとすると、表面上のプライマリキーのインデックスを探したうえで、さらに rowid のインデックスを探すことになる。つまり、このケースのプライマリキーとは単に UNIQUE なインデックスでしかない。
そこそこ最近(3.8.2・2013年)からは WITHOUT ROWID をテーブル定義時に指定することで、暗黙的な rowid 生成を抑制して、プライマリキー指定した定義を「真のプライマリキー」とすることができる。
これによって
と良いことがある。一方デメリットで気になるのは
TF-IDFによる類似エントリー機能の実装をしてみました。ほぼSQLiteですませるような構成です。
MeCab を使った形態素解析などでもいいのですが、お手軽にやりたかったので以下のようにしています。
my $text = ...;
$text =~ s{<style[^<]*?</style>}{}g;
$text =~ s{<script[^<]*?</script>}{}g;
$text =~ s{<[^>]+?>}{}g;
$text =~ s{[^\w]+}{ }g;
my $words = reduce {
$a->{$b}++;
$a;
} +{},
map {
s/^\s|\s$//g;
$_;
}
map {
if (/[^a-z0-9]/i) {
Text::TinySegmenter->segment($_);
} else {
$_;
}
} split /\s/, $text; 不必要なHTML要素及びタグを削除し、記号類を全てスペースに置換したうえでスペースで分割し、日本語が含まれていそうな部分だけ TinySegmenter による簡易形態素解析をしています。
自分しか書かない日記の類似をとるので、表記揺れが殆どないことを前提に、アルファベットだけで構成される部分に関してはそのまま特徴語としたいためです。また、プログラムについて書くことが多いので日本語部分は比較的重要度が低いという見立てがあります。
転置インデックスはあるワードがどのエントリに含まれるかを記録したデータ構造です。エントリー中の文章を適切な粒度で分割して、ワードからエントリーをひけるインデックスをつくります。
転置インデックスだけでも、あるワードが含まれるエントリーのリストを得るのは簡単になるので、例えば「共通ワードが多いエントリ同士は類似している」というスコアリングを採用するなら、転置インデックスのみで実現できます。
DBとしてSQLiteを使っているので、簡単な定義の単一テーブルだけを作ってなんとかしています。
CREATE TABLE tfidf (
`id` INTEGER PRIMARY KEY,
`term` TEXT NOT NULL,
`entry_id` INTEGER NOT NULL,
`term_count` INTEGER NOT NULL DEFAULT 0, -- エントリ内でのターム出現回数
`tfidf` FLOAT NOT NULL DEFAULT 0, -- 正規化前の TF-IDF
`tfidf_n` FLOAT NOT NULL DEFAULT 0 -- ベクトル正規化した TF-IDF
);
CREATE UNIQUE INDEX index_tf_term ON tfidf (`term`, `entry_id`);
CREATE INDEX index_tf_entry_id ON tfidf (`entry_id`); 見ての通りですがターム(ワード)とエントリIDでユニークなテーブルです。
エントリ内のHTMLを適当な粒度で分割したのち、このテーブルに入れています。この段階では term, entry_id, term_count だけ埋めます。
INSERT INTO tfidf (`term`, `entry_id`, `term_count`) VALUES (?, ?, ?); TF-IDFは特徴語抽出のアルゴリズムです。文書中のワード出現頻度 (Term Frequency) と、全文書中のワード出現頻度の逆数( Inverse Document Frequency) から、ある文書のあるワードがどれぐらいその文書を特徴付けているかをスコアリングできます。
転置インデックスから「共通ワードが多いエントリ同士は類似している」というスコアリングを使ってエントリを抽出すると、ワード数の多いエントリ同士は類似していなくても類似しているとスコアリングされてしまいます。
TF-IDF を使って各ワードに重み付けをすれば「特徴語の傾向が似ている文書は類似してる」というスコアリングにすることができます。
まずは後述する正規化を考えずにテーブルの tfidf カラムを埋めます。
-- SQRT や LOG を使いたいので
SELECT load_extension('/path/to/libsqlitefunctions.so');
-- エントリ数をカウントしておきます
-- SQLite には変数がないので一時テーブルにいれます
CREATE TEMPORARY TABLE entry_total AS
SELECT CAST(COUNT(DISTINCT entry_id) AS REAL) AS value FROM tfidf;
-- ワード(ターム)が出てくるエントリ数を数えておきます
-- term と entry_id でユニークなテーブルなのでこれでエントリ数になります
CREATE TEMPORARY TABLE term_counts AS
SELECT term, CAST(COUNT(*) AS REAL) AS cnt FROM tfidf GROUP BY term;
CREATE INDEX temp.term_counts_term ON term_counts (term);
-- エントリごとの合計ワード数を数えておきます
CREATE TEMPORARY TABLE entry_term_counts AS
SELECT entry_id, LOG(CAST(SUM(term_count) AS REAL)) AS cnt FROM tfidf GROUP BY entry_id;
CREATE INDEX temp.entry_term_counts_entry_id ON entry_term_counts (entry_id);
-- TF-IDF を計算して埋めます
-- ここまでで作った一時テーブルからひいて計算しています。
UPDATE tfidf SET tfidf = IFNULL(
-- tf (normalized with Harman method)
(
LOG(CAST(term_count AS REAL) + 1) -- term_count in an entry
/
(SELECT cnt FROM entry_term_counts WHERE entry_term_counts.entry_id = tfidf.entry_id) -- total term count in an entry
)
*
-- idf (normalized with Sparck Jones method)
(1 + LOG(
(SELECT value FROM entry_total) -- total
/
(SELECT cnt FROM term_counts WHERE term_counts.term = tfidf.term) -- term entry count
))
, 0.0) 一時テーブルを使いまくっています。何度も同じ TF-IDF 計算をするなら効率化のため保存しておけそうなテーブルもありますが、更新処理が複雑になるためTF-IDF更新時に作っては消しています。修正が頻発するような開発初期段階では特に一時テーブルは設計変更などに強くて便利です。
TF-IDF を計算して、エントリごとにエントリ中の単語数次数を持つ特徴ベクトルを作ったことになります。このあとコサイン類似度をとるわけですが、その際にはベクトルの大きさが不要なのでこれを正規化します。
ベクトル正規化はあるベクトルを方向(角度)をそのままに長さを1にするとこを言っています。コサイン類似ではエントリごとの角度だけを比較したいので、あらかじめ文書ごとのベクトルを正規化することで計算を簡単にできます。
-- エントリごとのTF-IDFのベクトルの大きさを求めておきます
CREATE TEMPORARY TABLE tfidf_size AS
SELECT entry_id, SQRT(SUM(tfidf * tfidf)) AS size FROM tfidf
GROUP BY entry_id;
CREATE INDEX temp.tfidf_size_entry_id ON tfidf_size (entry_id);
-- 計算済みの TF-IDF をベクトルの大きさで割って正規化します
UPDATE tfidf SET tfidf_n = IFNULL(tfidf / (SELECT size FROM tfidf_size WHERE entry_id = tfidf.entry_id), 0.0) コサイン類似はベクトル長さを無視しての角度の差を求めるためのアルゴリズムです。2つのベクトルの角度の差のコサインを求めます。例えば、2つのベクトルの角度差が0(一致している)場合、 = 1、90度(直交・相関関係なし) なら 、180度(負の相関)なら と、なります。
前もってベクトル正規化をしているのでかけ算と足し算だけで計算できます。
ただ計算が簡単とはいえ、候補エントリ数*関係するワード(ターム)の数だけレコードをひいてくる必要があるので結構大変になってしまいます。
ここの効率化方法があまり思いつかず以下にようにしています
特徴語の共通語が多い順で足切りをしているので、長いエントリほどここでは有利となってしまいます。また、極端に短いエントリに関しては100エントリ以上が同一数の共通語を持つ状態になる場合があり、このケースではスコアをつける前に「類似」と判定すべきエントリが確率的に足切りされてしまうので正確ではありません。
TF-IDF の大きい順に50件だけを採用しているので、正確なコサイン類似度ではありません (ベクトル正規化のときに使った次数と違う) が、無視しています。
うまくいった場合はスコアリングで上位に類似エントリが集まるようになります。
-- 類似していそうなエントリを共通語ベースでまず100エントリほど出します
CREATE TEMPORARY TABLE similar_candidate AS
SELECT entry_id, COUNT(*) as cnt FROM tfidf
WHERE
entry_id > ? AND
term IN (
SELECT term FROM tfidf WHERE entry_id = ?
ORDER BY tfidf DESC
LIMIT 50
)
GROUP BY entry_id
HAVING cnt > 3
ORDER BY cnt DESC
LIMIT 100
-- 該当する100件に対してスコアを計算してソートします
SELECT
entry_id AS eid,
SUM(a.tfidf_n * b.tfidf_n) AS score
FROM (
(SELECT term, tfidf_n FROM tfidf WHERE entry_id = ? ORDER BY tfidf DESC LIMIT 50) as a
INNER JOIN
(SELECT entry_id, term, tfidf_n FROM tfidf WHERE entry_id IN (SELECT entry_id FROM similar_candidate)) as b
ON
a.term = b.term
)
WHERE eid != ?
GROUP BY entry_id
ORDER BY score DESC
LIMIT 10 これによって求められた類似エントリは別途テーブルに保存しておいて、表示時にはこのテーブルのみをひいてくる構成にしました。
結構みてる気がする

久しぶりに CD を買った。原点回帰っぽい構成みたいだけど、どうなんだろうな〜
ところで久しぶりにリッピングしようと思ったら CD ドライブがついているPCが起動せず、面倒なのでドライブを買った……

ASUS外付けDVDドライブ 軽量薄型/M-DISC/バスパワー/Win&Mac/USB2.0(USB3.0搭載PCでも利用可能)/書込みソフト付属/ブラック SDRW-08D2S-U LITE cho45
前までは EAC でリッピングしていた記憶があるけど、今回は iTunes でリッピングした。CDDB がまだ生きてて簡単だった。
自宅にいくつか Anker の充電器はあるが、Quick Charge 付きのものはなかった。そして、充電器いくつかあるとはいえ、旅行にいこうとすると足りなくて不便だった。
ということで上記のものを買った。ポート数多くなって便利。
Zenfone2 は Quick Charge 2.0 対応なので (特にそうとは書いてないが 9V 充電可能)、繋ぐと以下のように「急速充電中」とともに、発熱に関しての警告がマーキーで表示される。
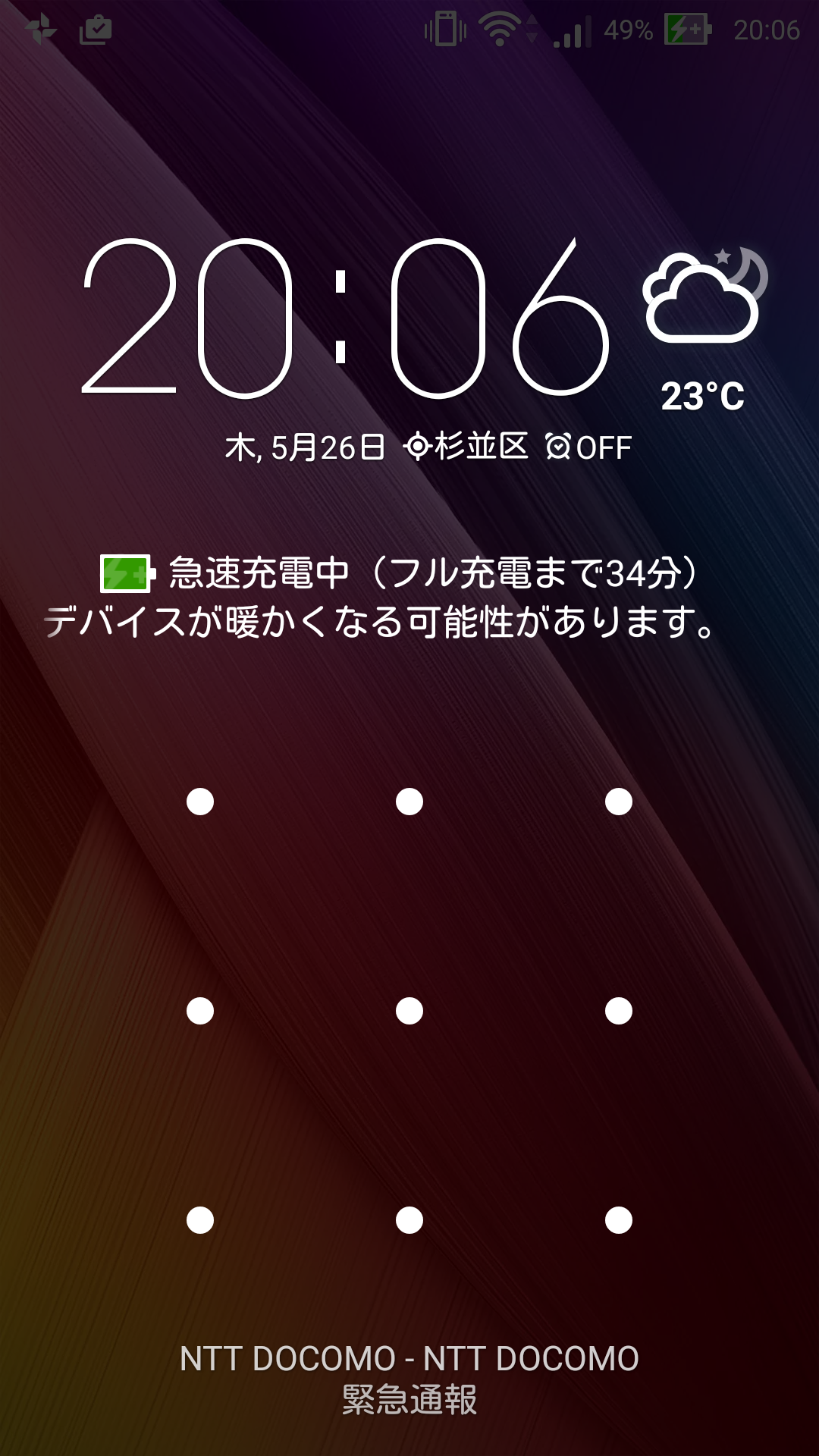
ただ、Quick Charge 対応ポートは1つだけなので、急速充電したいときは気をつける必要がある。USBケーブルをQuick Charge ポートだけ色が違うものにした。